作为一个 3D 的项目,从用户打开页面到最终模型的渲染需要经过多个流程,加载的时间也会比普通的 H5 项目要更长一些,从而造成大量的用户流失。为了提升首屏加载的转化率,需要尽可能的降低 loading 的时间。这里就分享一些我们在模型加载优化方面的心得。
# 一、前言
近段时间,我们使用 three.js 完成了 vivo 拟我形象的开发工作,大家可以在 vivo 账号中拟制属于自己的 3D 形象,也可以保存作为自己的头像名片。
作为一个 3D 的项目,从用户打开页面到最终模型的渲染需要经过多个流程,加载的时间也会比普通的 H5 项目要更长一些。然而过长的等待时间会造成大量的用户流失,这部分用户没有体验到具体的功能就退出了页面非常的遗憾,为了提升首屏加载的转化率,需要尽可能的降低 loading 的时间。这里就分享一些我们在模型加载优化方面的心得。
# 二、模型加载的优化思路
想对加载进行优化,首先需要了解 Three.js 加载模型时的工作流程,并分析出其中耗时的部分进行针对性的处理。
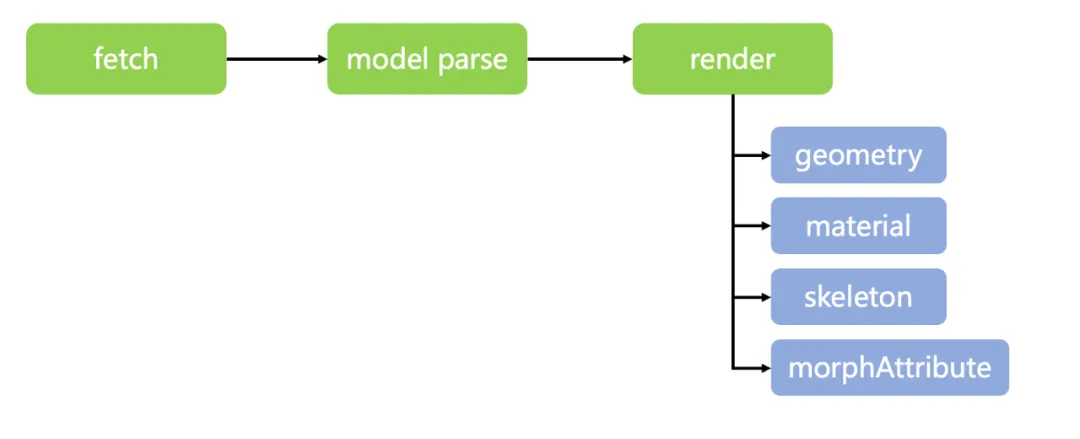
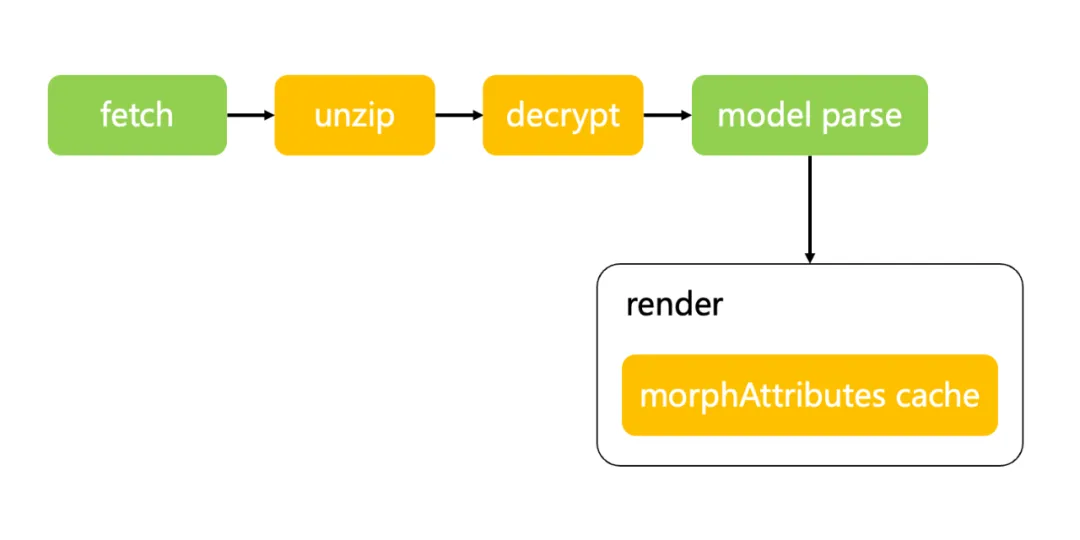
在 Three.js 中,模型从加载到渲染需要经过模型下载、序列化模型、网格解析、写入缓存和渲染模型几个步骤,经过分析发现主要的瓶颈在网络请求和网格解析两个部分,所以整体的优化思路就是减少网络请求资源的体积和提升网格的解析速度。
# 三、缩小模型的体积
# 3.1 常见的解决方案
目前主流的压缩方案是使用 google 的 draco 库对模型进行压缩。draco 的原理类似降低图片的分辨率,通过减少模型的顶点数起到压缩体积的效果。
也就是说 draco 是一种有损的压缩方式,这样就会带来诸多的问题:
- 可能在网格连接处存在画面模型撕裂。
- 仅仅压缩顶点只能将 50.7mb 的人物模型压缩到 49.5,压缩效果有限。
- draco 前台 decoder 在 h5 中的解算效率不理想,可能节省下来的网络请求时间还没有增加的数据解算的时间长。
基于以上几点,最终我们放弃了 draco 的压缩方案。
使用 draco 压缩之后导致的模型撕裂
# 3.2 进阶方案
高端的食材,往往只需要采用最朴素的烹饪方式。经过一些尝试,我们发现将 glb 模型直接打成 zip 包可以明显的提升模型的压缩效率。50.7mb 的人物模型可以压缩到 11.6mb。
 |  |
|---|
但是 Three.js 提供的 gltfloader 是不能直接加载 zip 文件的,于是我们需要对其进行功能扩展。
Three.js 加载 gltf 模型是首先通过 fetch 请求获取到模型的 arraybuffer,再对 arraybuffer 进行格式化。所以我们只需要在模型格式化之前拦截 zip 文件进行解压缩即可。
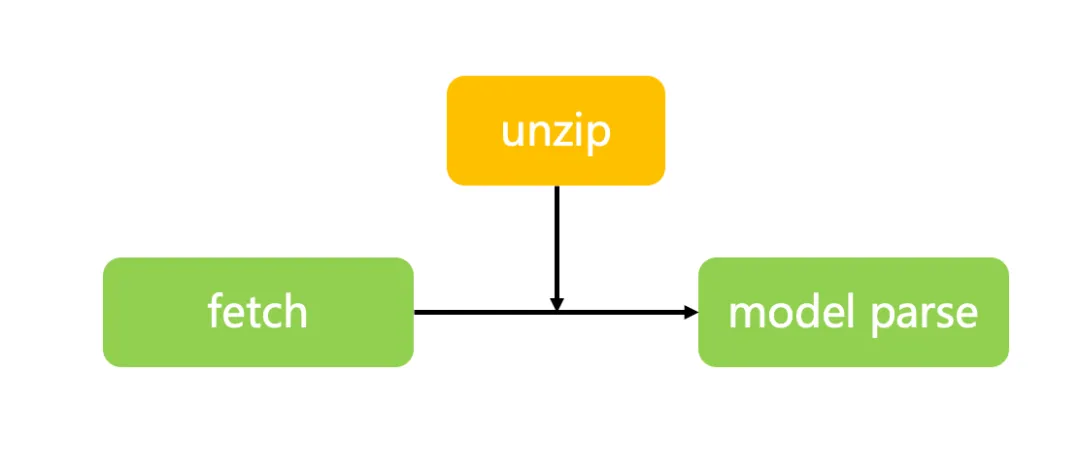
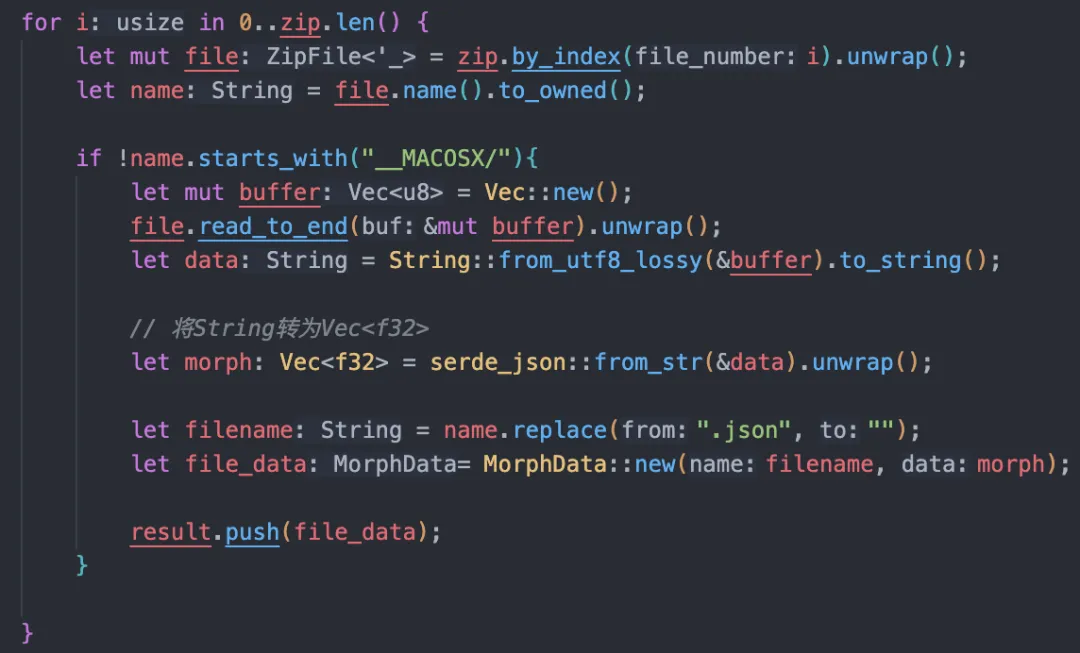
于是我们使用 jszip,资源加载完成后判断资源的后缀,如果是 zip 文件就使用 jszip 进行解压缩。

看起来还不错,在保证视觉效果的同时又可以大幅压缩模型的体积,那么有没有可能做的再极致一些呢?
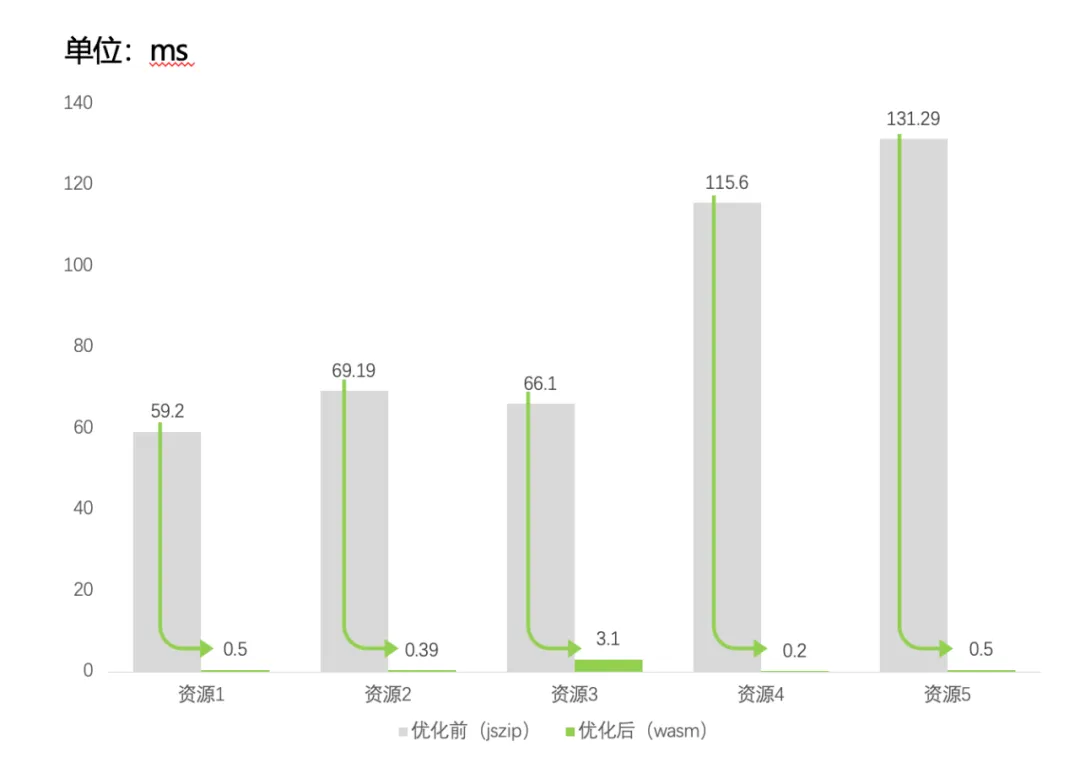
既然是针对性的场景,我们就可以从解压缩的解算开始入手,于是我们使用 rust 写了一个解压工具,将其转换成 wasm 包代替 jszip,可以发现 wasm 的冷启动性能确实要比 js 好很多,可以将解压的时长从几十到 100 毫秒降低到 1 毫秒左右,适合体积比较小的解压缩场景。

# 四、文件的加解密
作为一个 h5 项目,获取到静态资源的链接并不困难,所以需要对模型文件进行一点点加密,让破解起来没有那么容易。同时解密的过程不能显著延长资源加载的时间,影响用户体验。
基于数据解密的效率,我们可以截取文件 buffer 的一部分进行加密,而不对全文进行加密,同时将数据解密的过程也放到 wasm 中,提升解算效率的同时也增强了安全性。采用对称加密的算法,同一个方法既可以用于加密,也可以用于解密。
按照模型加载的流程,解密的操作应该放在解压缩之后,序列化之前,那么如何判断数据是否进行了加密呢,可以通过判断解压数据 decode 以后是否有 glTF 的标记来确定。

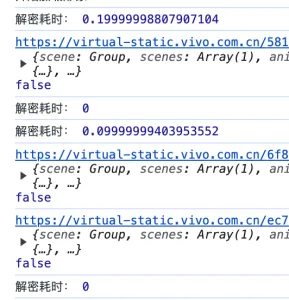
如下图,数据解密的耗时几乎可以忽略不计,可以放心使用。
# 五、如何优化首帧的渲染体验
优化完模型的加载,继续来优化模型的渲染,在加载一个体积比较大的模型的时候经常会有页面的卡死的情况出现,需要从两方面治标也治本的进行优化:
- 通过减少页面的卡停来优化用户的感官体验。
- 通过缩短首屏渲染的时长来解决根本问题。
# 5.1 减少页面的卡停
在模型加载的时候通常会设置一个 loading 页面来展示当前的加载进度,同时 loading 页也可以播放一些动效或者互动来让用户等待的过程中不那么无聊。但是由于 js 单线程的特性,在进行首帧渲染的时候任何事件都不无法响应,会让用户误以为页面卡死,造成流失。
为了解决这个问题我们可以使用分步加载的方案,在模型加载的时候先遍历第一层网格,将所有的网格隐藏起来,然后循环这些网格,每展示一个就执行一次 render 方法,这样就可以把一个大的卡顿分散成多个小的,不至于影响前台的体验。
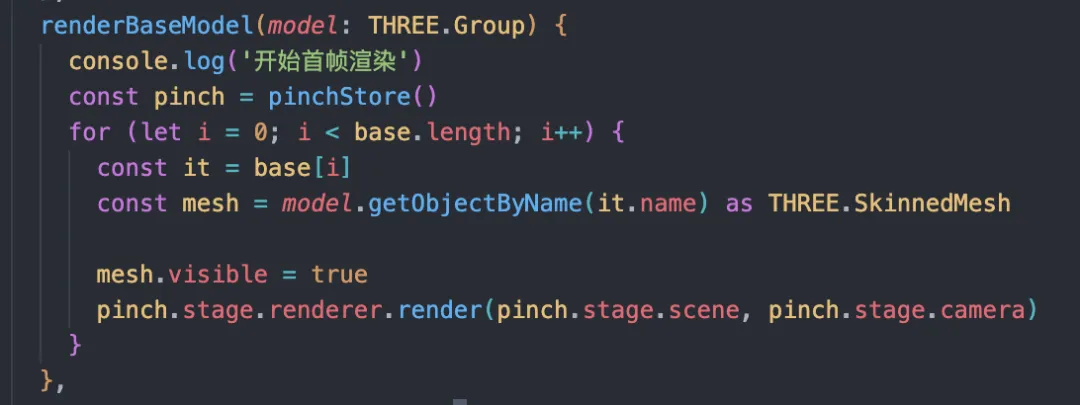
但是这样的方法只能让用户感受起来没那么卡顿,该等的时间一点没少,过长的等待时间还是会让用户等的不耐烦,有没有其他解决卡顿的方式呢?这就要从 Three.js 的渲染逻辑来进行分析了。
# 5.2 缩短首帧渲染的时间
由于我们做的是一个捏脸的项目,通过形态键来实现不同的脸型,表情等表现。在 Three.js 中存储形态键信息的属性在 geometry.morphAttributes 中,形态键存放的顶点信息总数与网格的顶点数相同,这就意味着同一个模型有多少个形态键,就额外需要加载多少套网格的顶点信息。在首次渲染的时候 Three.js 会遍历每一个形态键的顶点信息,生成一个 float32array,而这个巨量的遍历操作就是造成卡顿的根本原因。
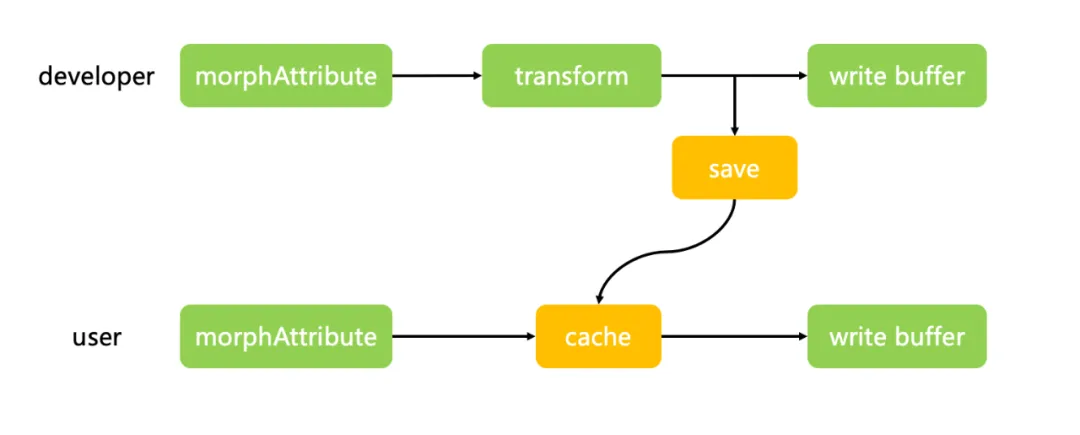
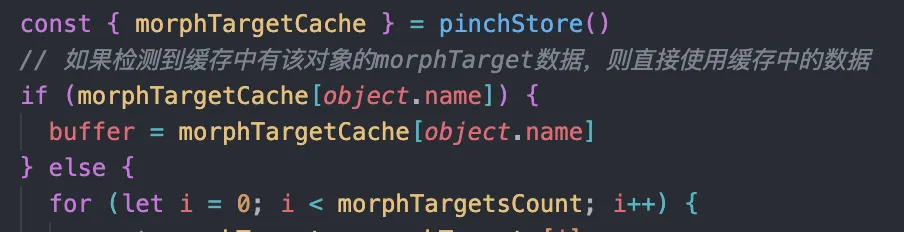
如何解决这个循环黑洞呢,我想到了 steamdeck 上的着色器预缓存,通过将着色器编译的结果进行持久化,缩短页面加载的时间。那么我们只要将每一个网格的形态键编译的结果储存起来就行了。
/three/src/renderers/webgl/WebGLMorphtargets.js
通过这种方式成功的将首帧渲染的时间从 7 秒缩短到 0.6 秒,大幅的提升了用户的体验。
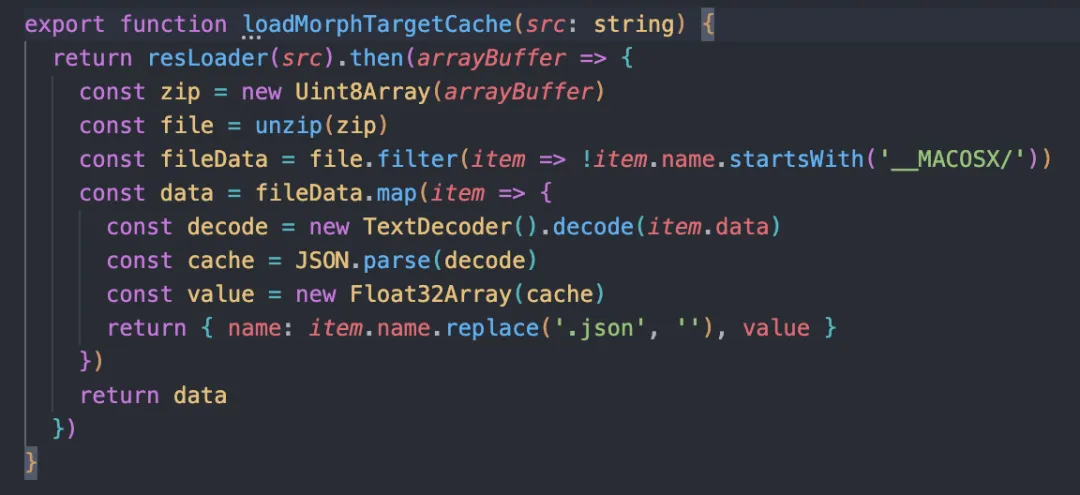
讲到这里,大家可能发现了,虽然首帧渲染的时长缩短了,但是形态键缓存的资源有 80mb,压缩后也有 15mb,这块的时长可不可以继续压榨呢,先看一下资源的处理流程,处理解压后的文件需要将文件解析成 JSON 字符串,然后在转换成 float32array,这里耗时最大的点就是 JSON.parse 的操作,有没有更好的方式处理呢,可以将这部分内容丢到 rust 里面,平均可以减少 0.5s 的时间。
# 六、总结与规划
以上就是我们的优化流程,将 glb 模型文件压缩成 zip 包,配合前台 wasm 解压工具降低模型的加载时间。通过增加形态键缓存的方式来降低首帧渲染的时长。
经过这一系列的操作,成功的将模型的体积从 50mb 压缩到 11mb,增加了额外 80mb 的形态键缓存也可以使用 zip 压缩到 15mb,处理后页面的首次加载时长从 15 秒缩短到 5 秒,算是一个不小的提升。
然而,我们也意识到还有进一步的优化空间,譬如目前虽然有了形态键缓存,但是原模型中的形态键信息还存储在模型中,这一部分的信息不需要被 threejs 读取,却很大的占用了模型的体积,后续可以开发一个 gltf-pipeline 类似的处理工具,将形态键缓存直接整合进 gltf 模型中,同时把整个模型的序列化工作放到 wasm 中处理,降低模型的尺寸的同时也可以减少模型解析的时长。期待为大家带来更好的使用体验。