背景: redis 字典(hash 表)当数据越来越多的时候,就会发生扩容,也就是 rehash
** 对比:**java 中的 hashmap,当数据数量达到阈值的时候 (0.75),就会发生 rehash,hash 表长度变为原来的二倍,将原 hash 表数据全部重新计算 hash 地址,重新分配位置,达到 rehash 目的
# redis 中的 hash 表采用的是渐进式 hash 的方式:
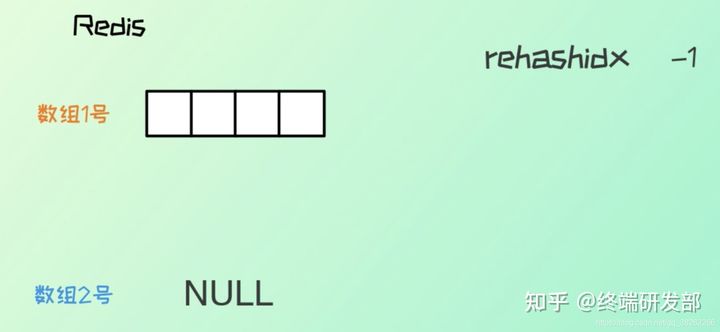
1、redis 字典(hash 表)底层有两个数组,还有一个 rehashidx 用来控制 rehash

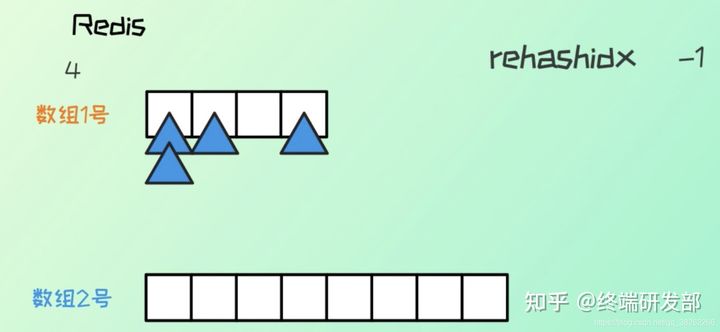
2、初始默认 hash 长度为 4,当元素个数与 hash 表长度一致时,就发生扩容,hash 长度变为原来的二倍
3、redis 中的 hash 则是执行的单步 rehash 的过程:
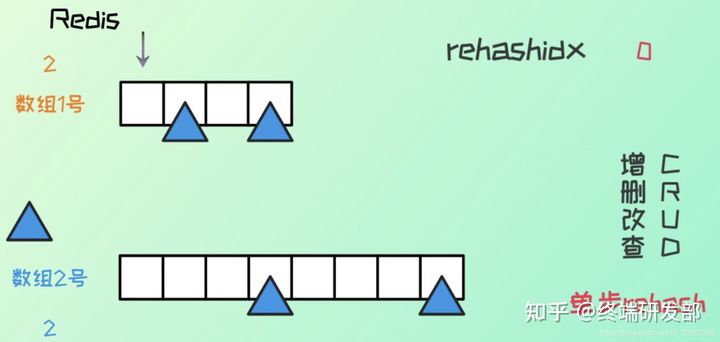
每次的增删改查,rehashidx+1,然后执行对应原 hash 表 rehashidx 索引位置的 rehash
# 总结:
在扩容和收缩的时候,如果哈希字典中有很多元素,一次性将这些键全部 rehash 到 ht[1] 的话,可能会导致服务器在一段时间内停止服务。所以,采用渐进式 rehash 的方式,详细步骤如下:
- 为
ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表 - 将
rehashindex的值设置为0,表示 rehash 工作正式开始 - 在 rehash 期间,每次对字典执行增删改查操作是,程序除了执行指定的操作以外,还会顺带将
ht[0]哈希表在rehashindex索引上的所有键值对 rehash 到ht[1],当 rehash 工作完成以后,rehashindex的值+1 - 随着字典操作的不断执行,最终会在某一时间段上
ht[0]的所有键值对都会被 rehash 到ht[1],这时将rehashindex的值设置为-1,表示 rehash 操作结束
渐进式 rehash 采用的是一种分而治之的方式,将 rehash 的操作分摊在每一个的访问中,避免集中式 rehash 而带来的庞大计算量。
需要注意的是在渐进式 rehash 的过程,如果有增删改查操作时,如果 index 大于 rehashindex ,访问 ht[0] ,否则访问 ht[1]。
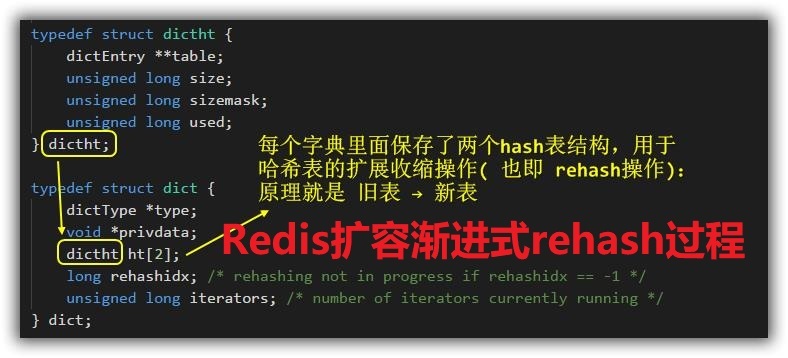
# 补充一下 Redis 的字典由 dict.h/dict 结构如下(rehash 的重点)
typedef struct dict { | |
//类型特性函数 | |
dictType *type; | |
//私有数据 | |
void *privdata; | |
//哈希表 | |
dictht ht[2]; | |
//rehash索引 | |
//当rehash没有进行时为-1 | |
int trehashidx; | |
} |
ht 属性是一个包含两个项的数组,数组中的每个项都是一个 dictht 哈希表,一般情况下使用的都是 ht [0] 的哈希表,而 ht [1] 的哈希表只会在 rehash 的时候使用。
随着操作的进行,哈希表中的键值对会逐渐增多或减少,这时为了让哈希表负载因子位置在一个合理的范围之内就会对哈希表大小进行扩展或收缩即 rehash。