为什么要学习内存管理以及垃圾回收算法?
JavaScript 中的内存释放是自动的,释放的时机就是某些值(内存地址)不在使用了,JavaScript 就会自动释放其占用的内存。其实大多数内存管理的问题都在这个阶段,在这里最艰难的任务就是找到那些不需要的变量。现在打高级语言都有自己垃圾回收机制,虽然现在的垃圾回收算法很多,但是也无法智能的回收所有的极端情况。
# 内存管理
不论什么样的编程语言,在代码执行的过程中都是需要给他分配内存的,有些编程语言(C、C++)需要我们自己手动管理内存,例如C语言,他们提供了内存管理的接口,比如malloc()用于分配所需的内存空间,free()用于释放之前所分配的内存空间。有的编程语言(Java、JavaScript)会自动帮我们管理内存 |
不论是手动还是自动,内存的管理都会有如下生命周期:
第一步:内存分配:例如当我们定义变量时,系统会自动为其分配内存
第二步:内存使用:在对变量进行读写时发生,(存放一些东西,比如对象,变量)
第三步:内存回收不需要使用时,对其进行释放
注意:后续画内存图补充相关原理
我们可以看一下内存泄漏的例子:
<!DOCTYPE html> | |
<html lang="en"> | |
<head> | |
<meta charset="UTF-8"> | |
<meta http-equiv="X-UA-Compatible" content="IE=edge"> | |
<meta name="viewport" content="width=device-width, initial-scale=1.0"> | |
<title>Document</title> | |
</head> | |
<body> | |
<button class="create">创建一系列数组对象</button> | |
<button class="destroy">销毁一系列数组对象</button> | |
<script> | |
function createArray() { | |
// V8 引擎中小的数字占 4 个字节 | |
var arr = new Array(1024 * 1024).fill(100) | |
function test() { | |
console.log(arr); | |
} | |
return test | |
} | |
// 点击按钮 | |
var totalArr = [] | |
var createBtnE1 = document.querySelector(".create") | |
var destroyBtnE1 = document.querySelector(".destroy") | |
createBtnE1.onclick = function() { | |
for(i = 0; i < 100; i++) { | |
totalArr.push(createArray()) | |
} | |
} | |
destroyBtnE1.onclick = function() { | |
totalArr = null | |
// totalArr = [] | |
} | |
</script> | |
</body> | |
</html> |
第一步,我们先看用户未经过任何操作,内存的快照如下图: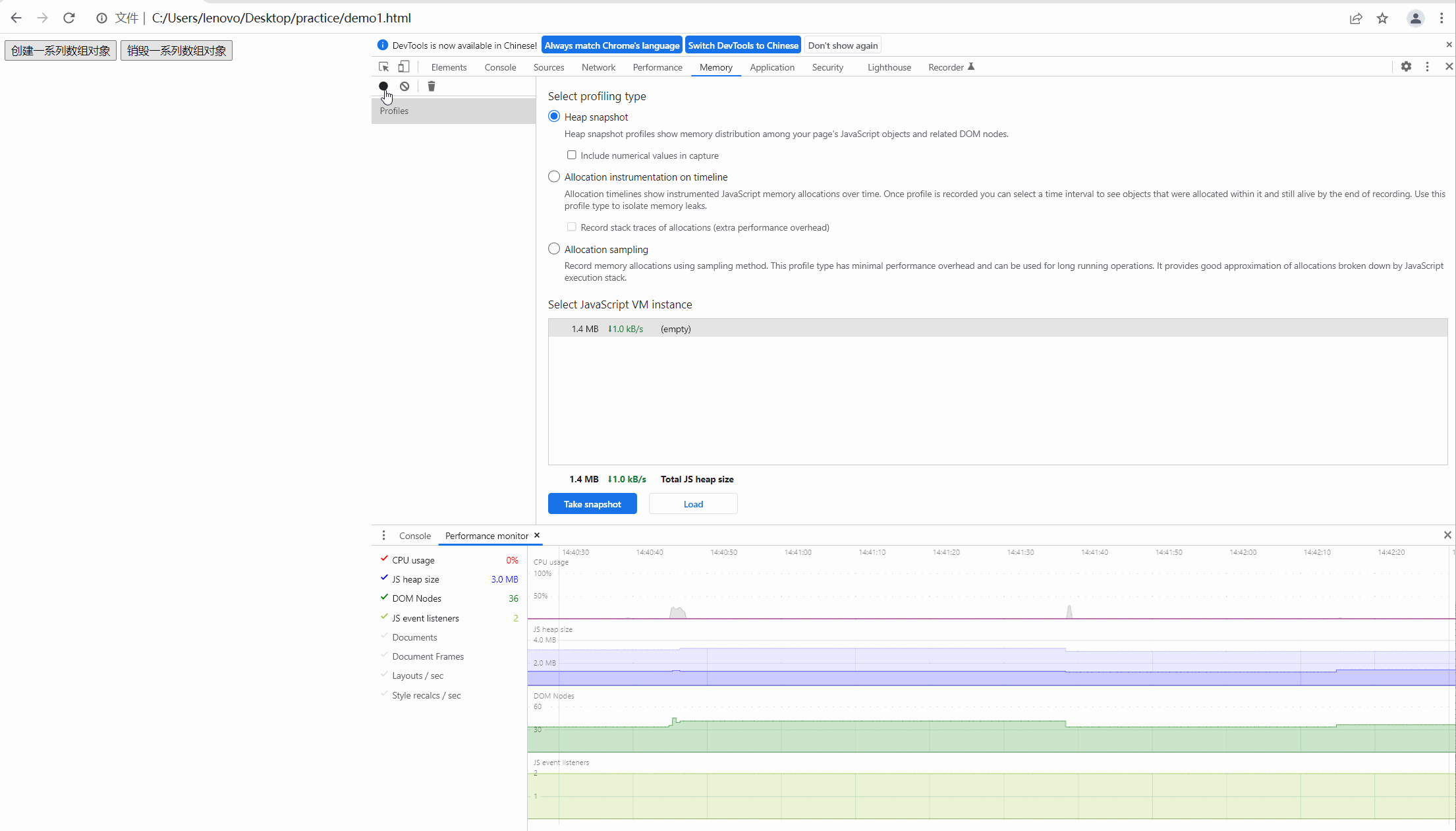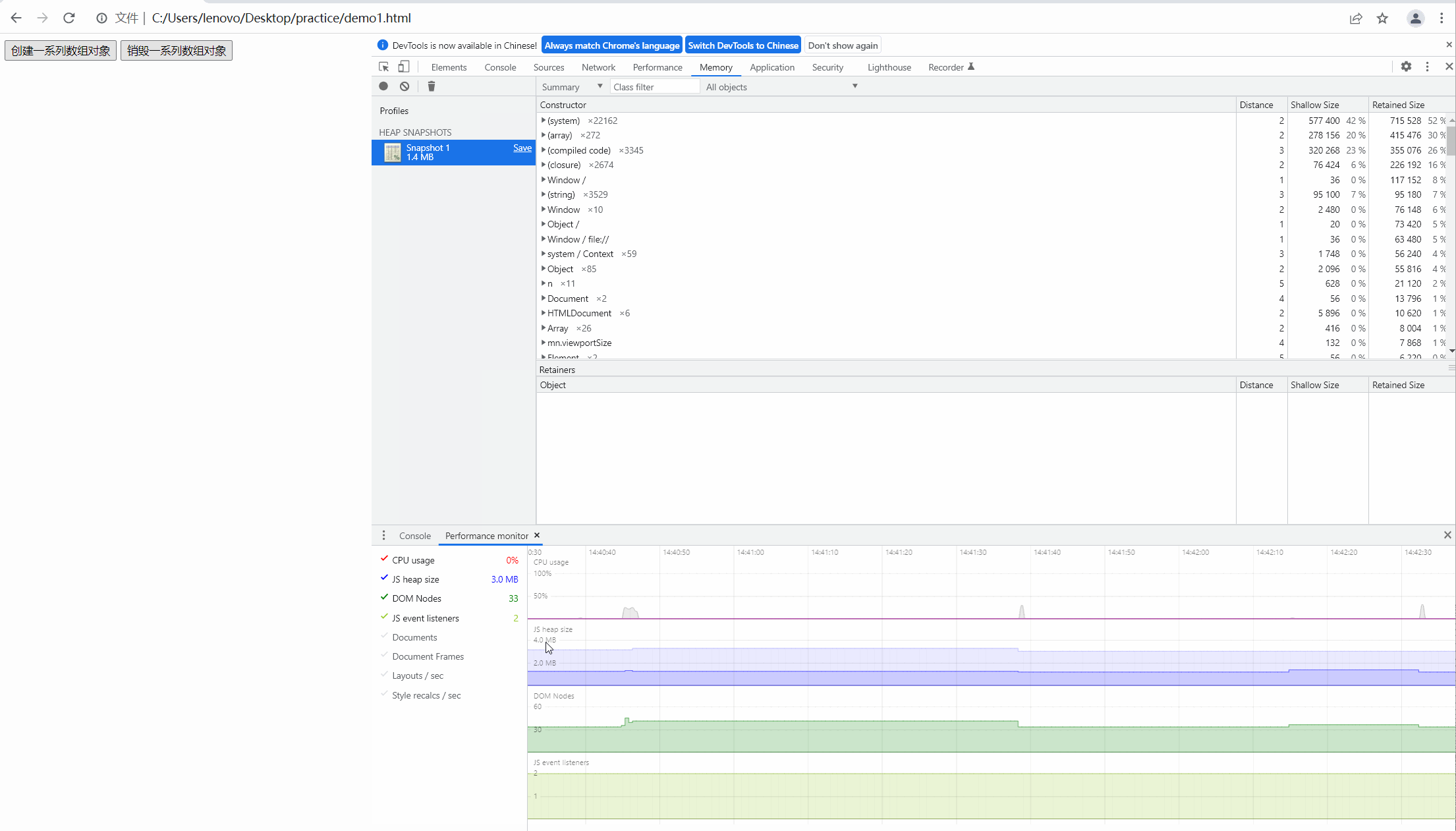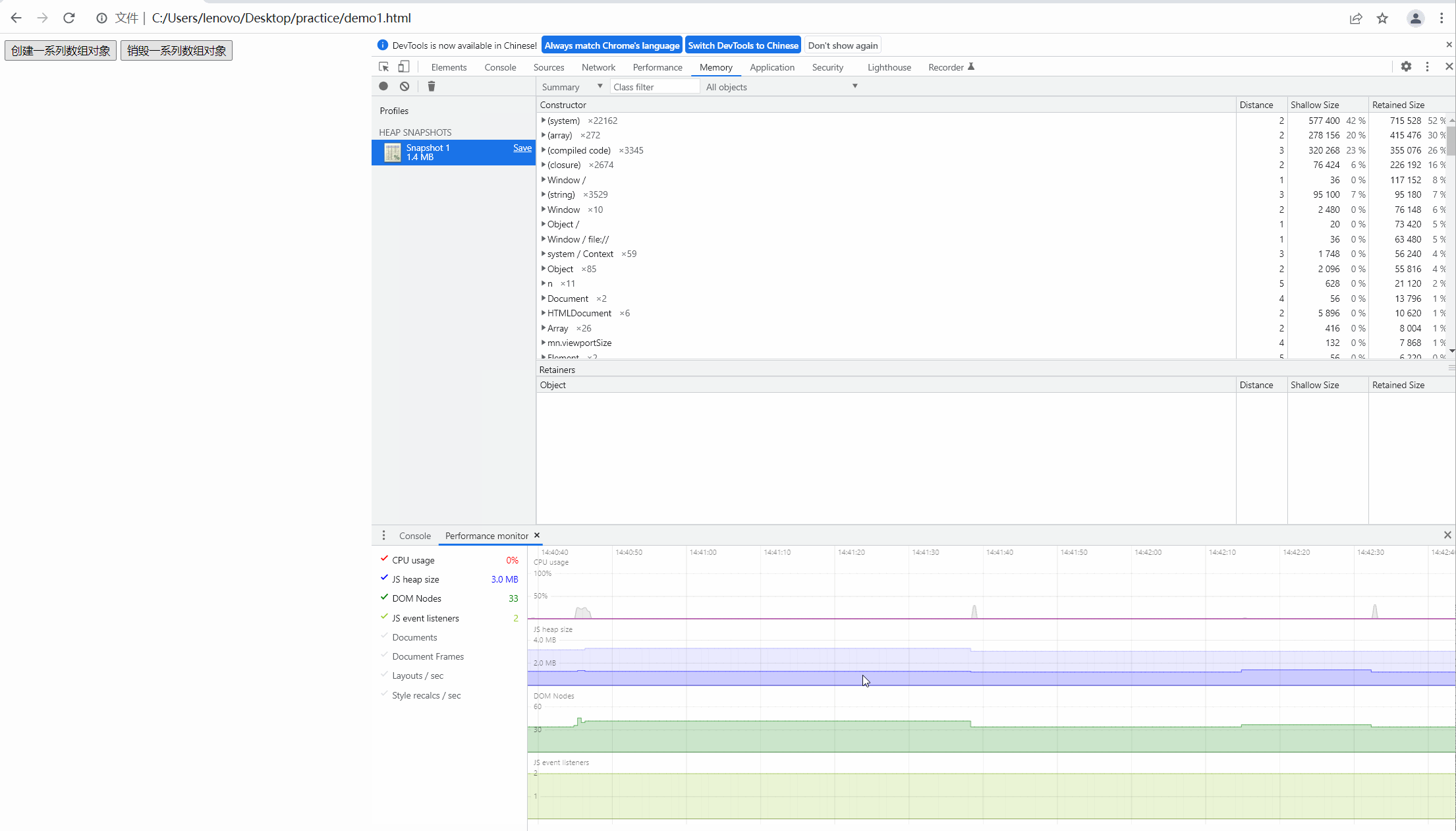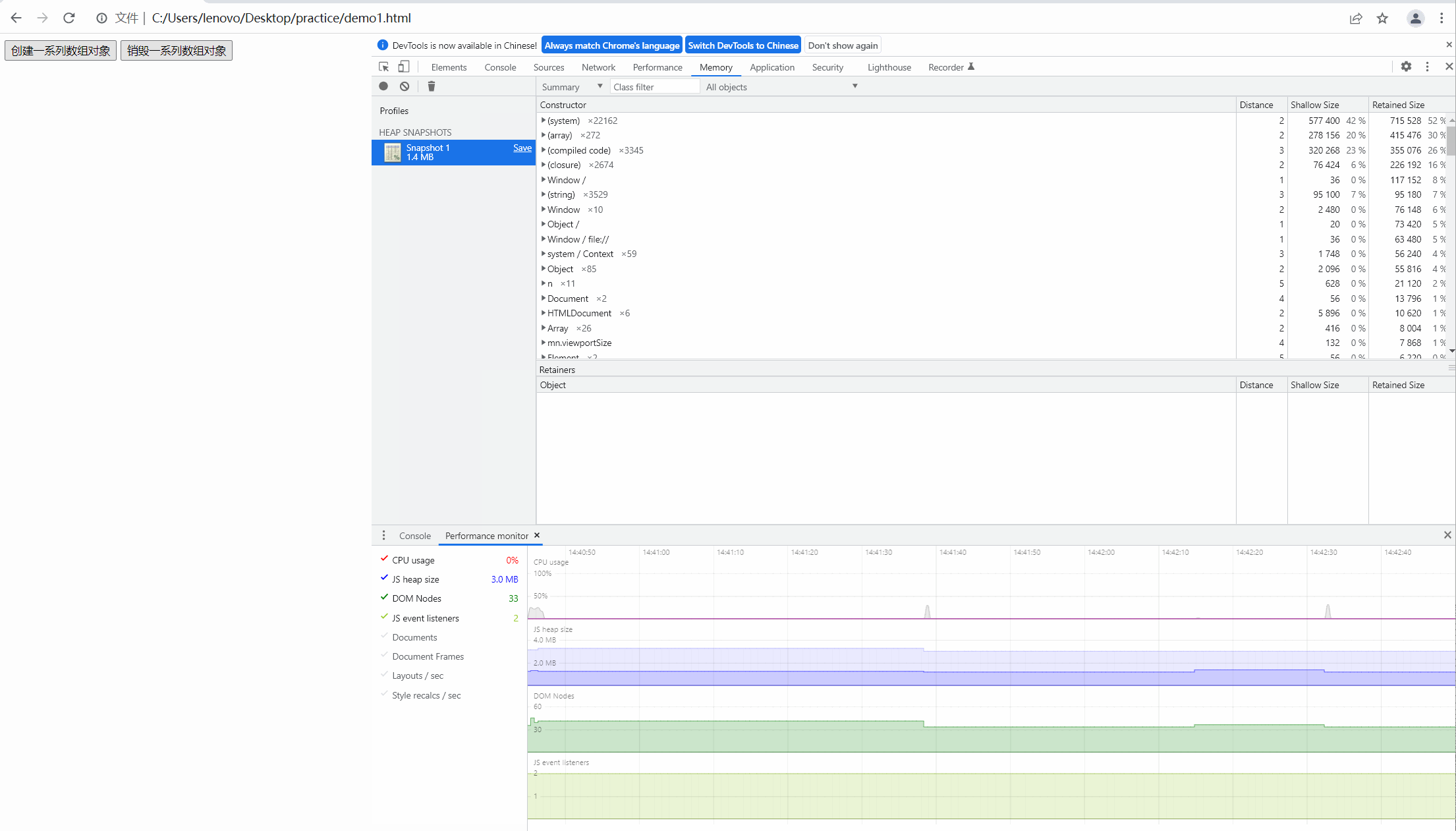
此时未经过任何操作,发现 js heap size 中几乎保持平稳的趋势
第二步,我们点击按钮,创建数组,观察内存的快照如下图:
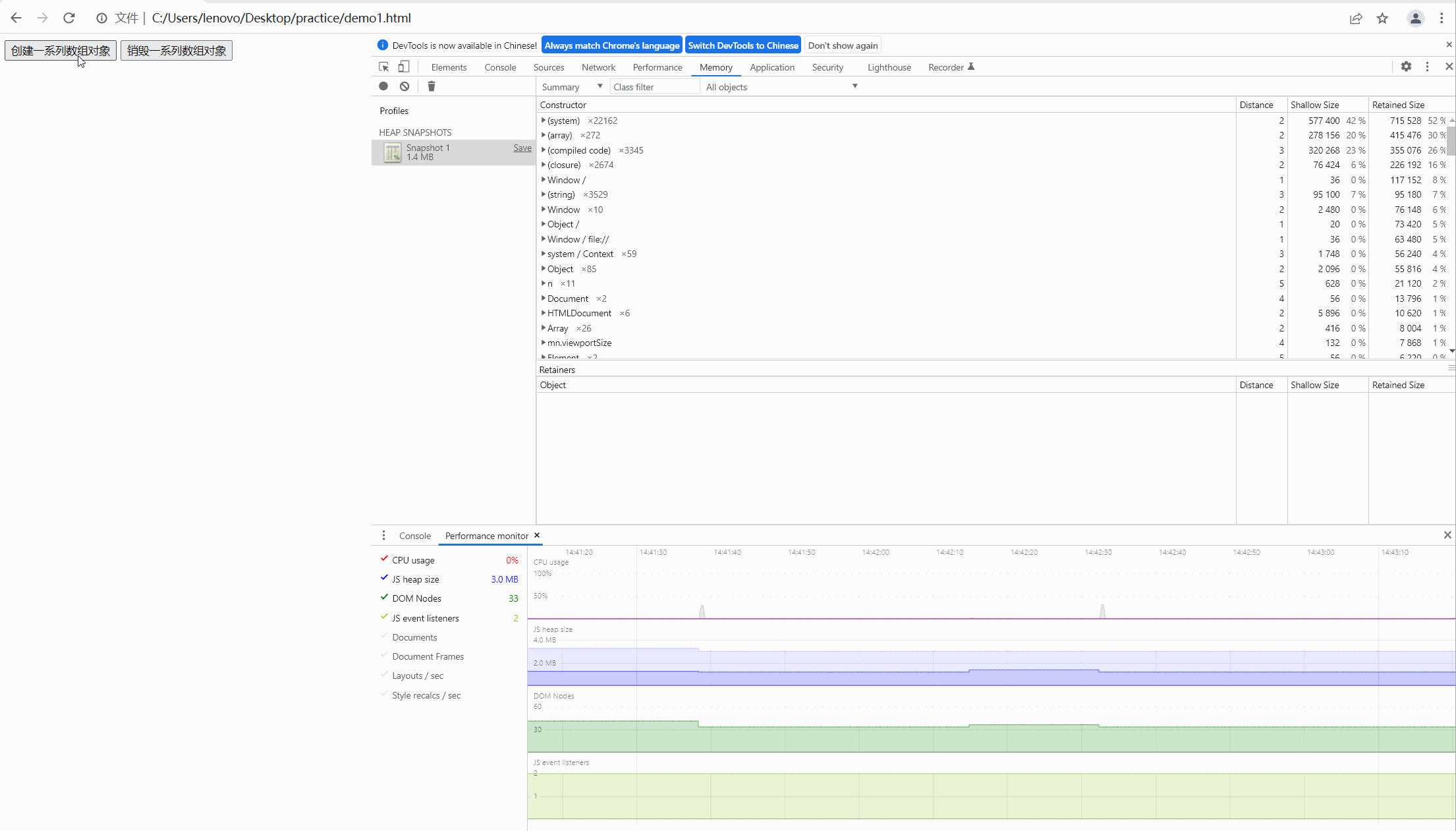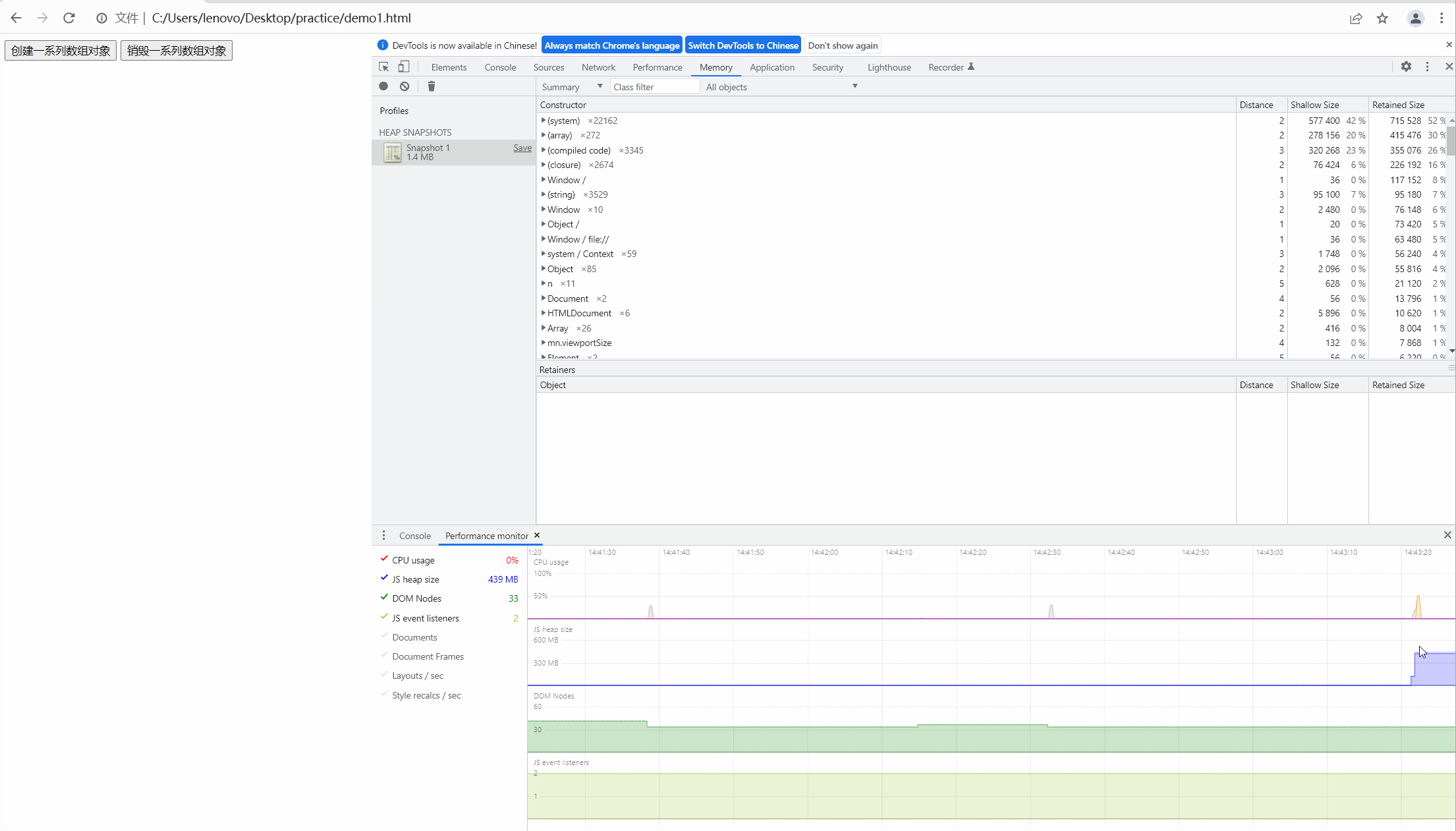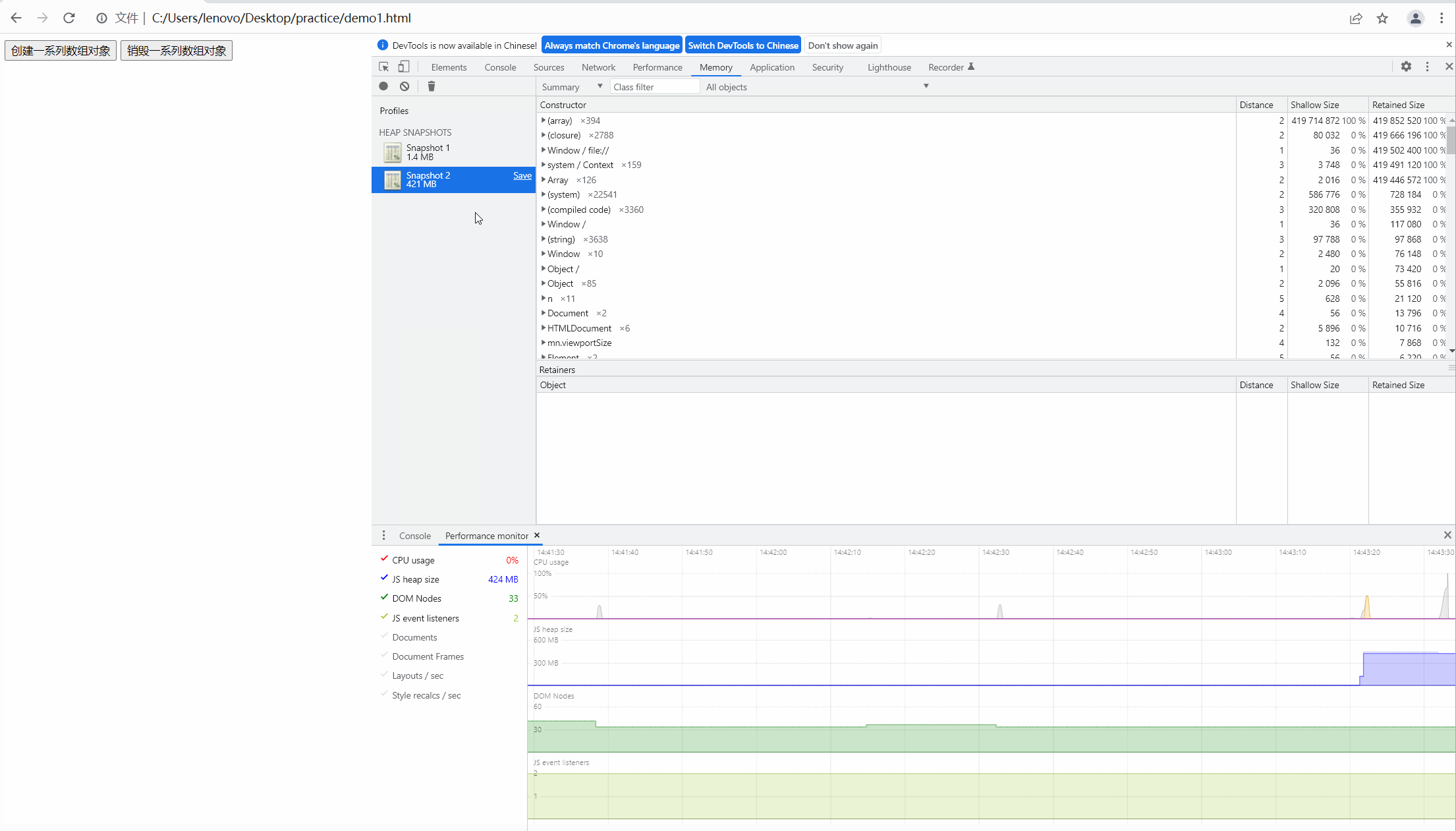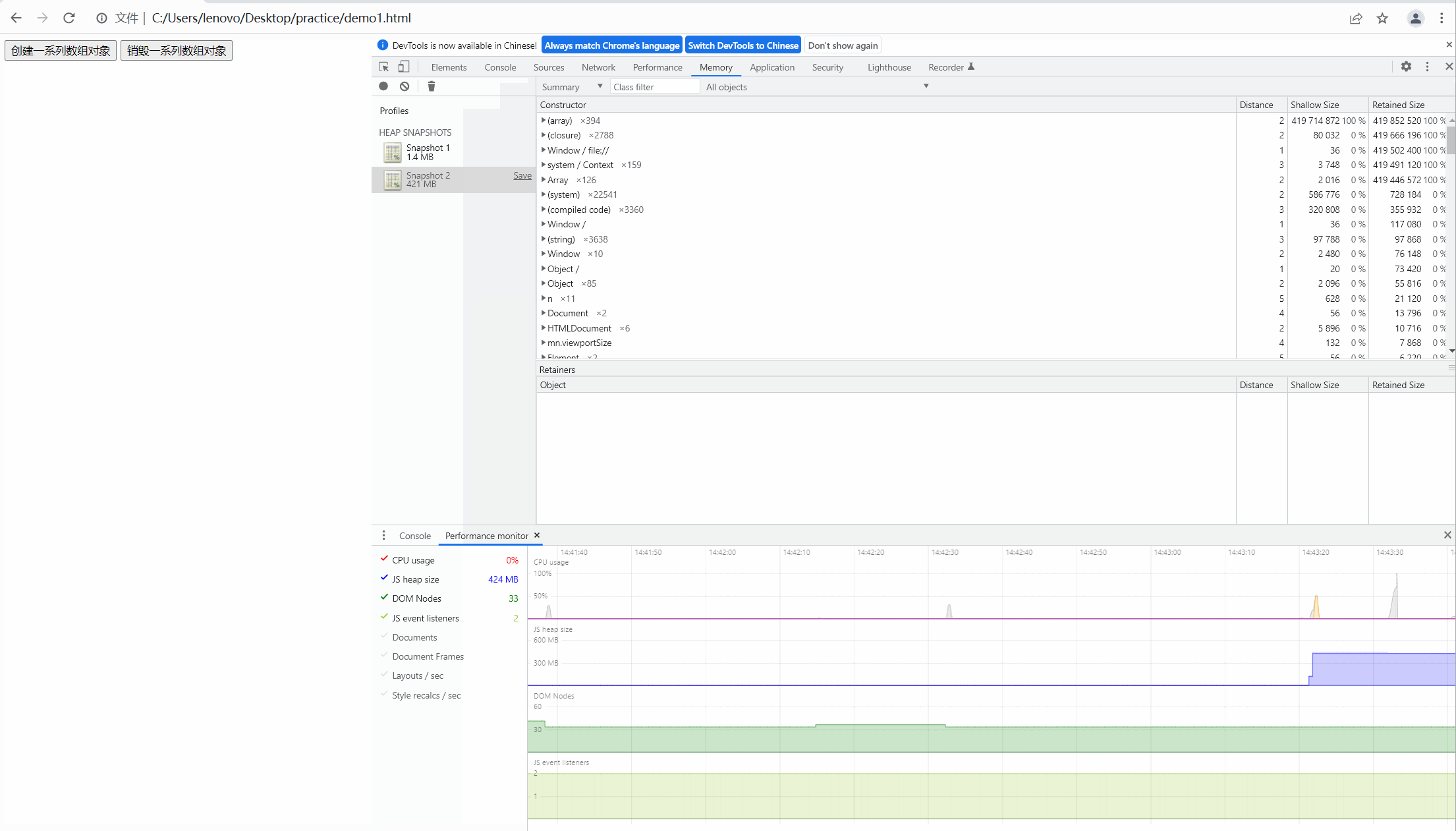
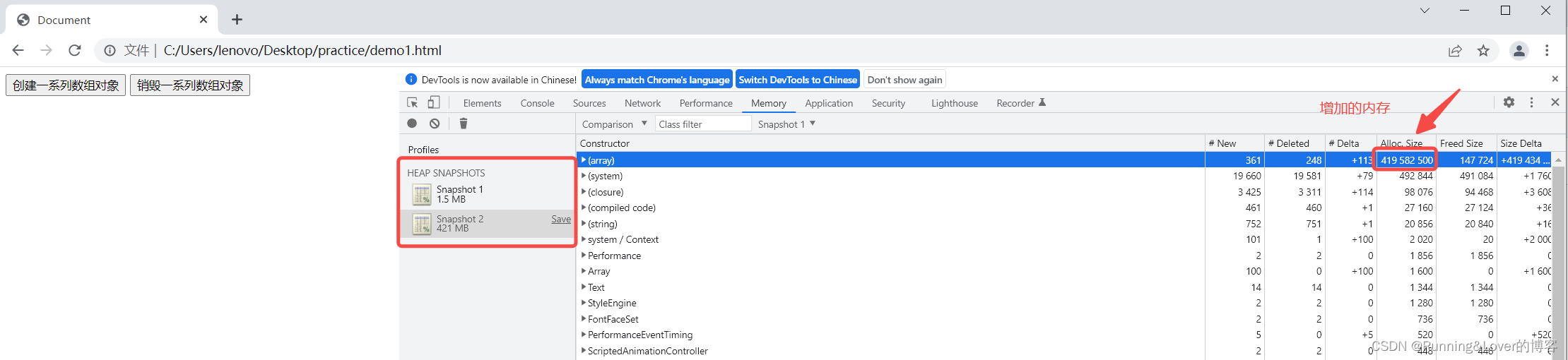
可以看到内存飙升,从大约一兆上升到四百多兆,很明显内存泄露了。
最后,我们点击销毁按钮,对没有进行自动释放的内存进行手动释放,效果图如下:
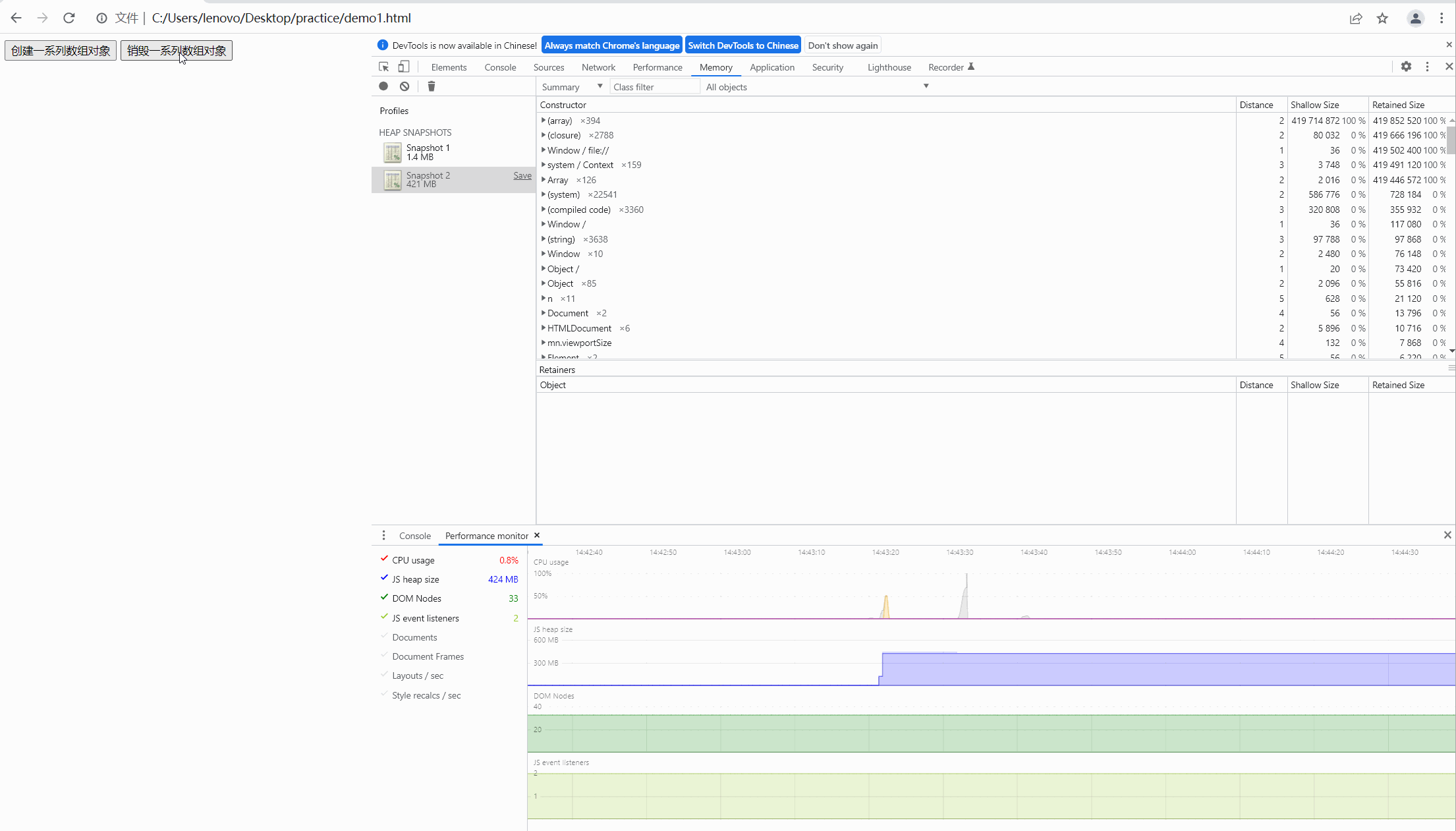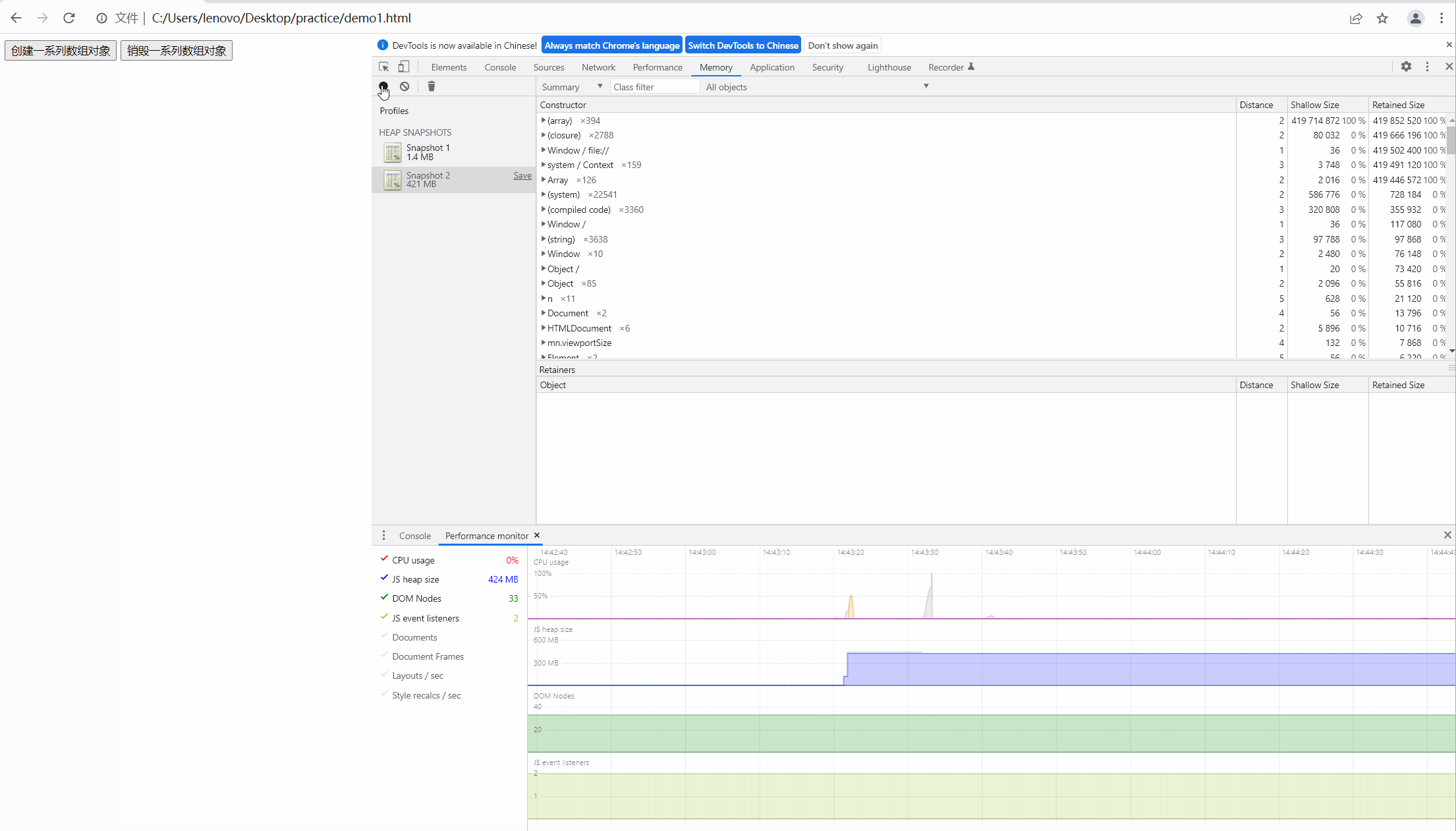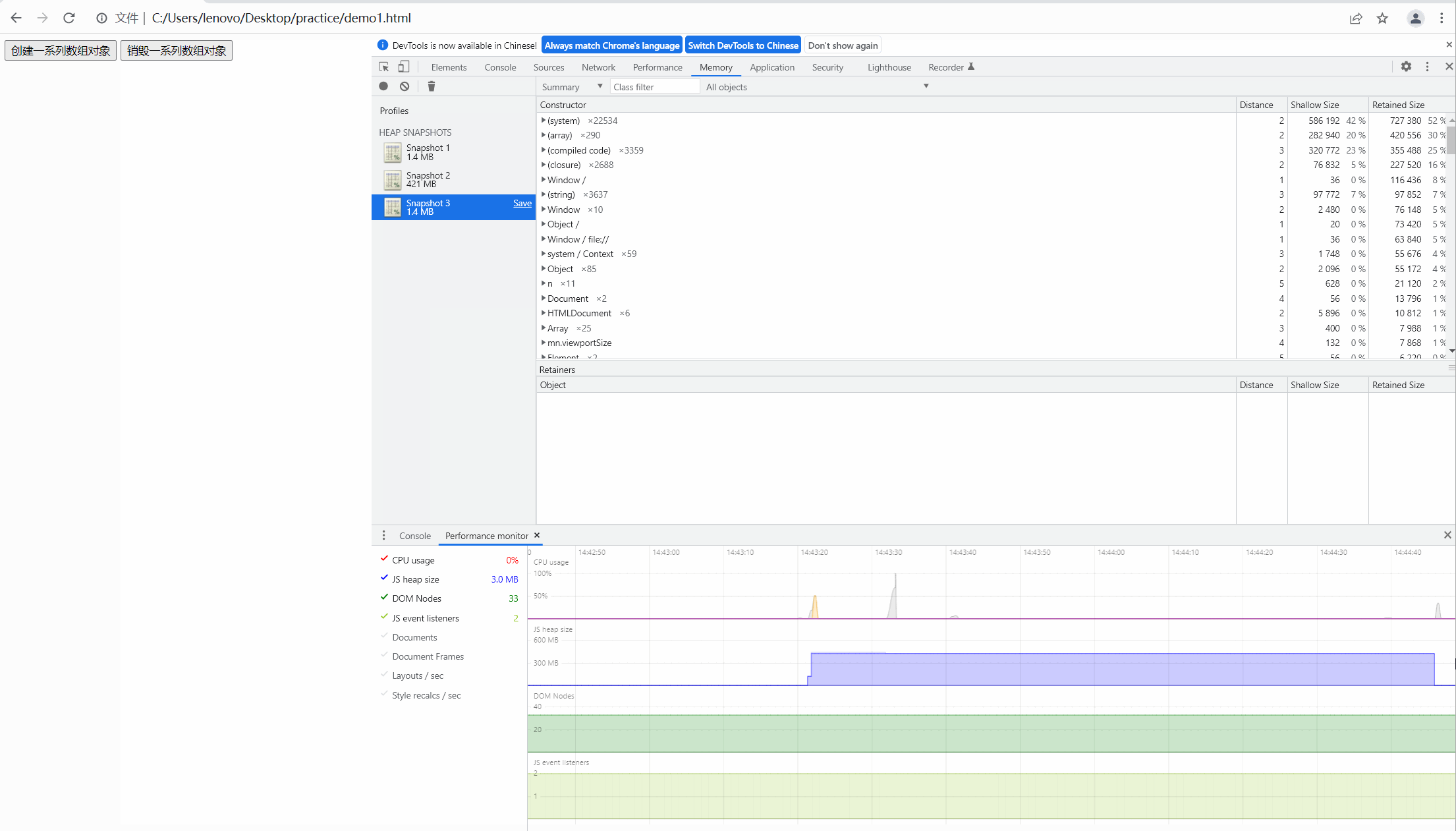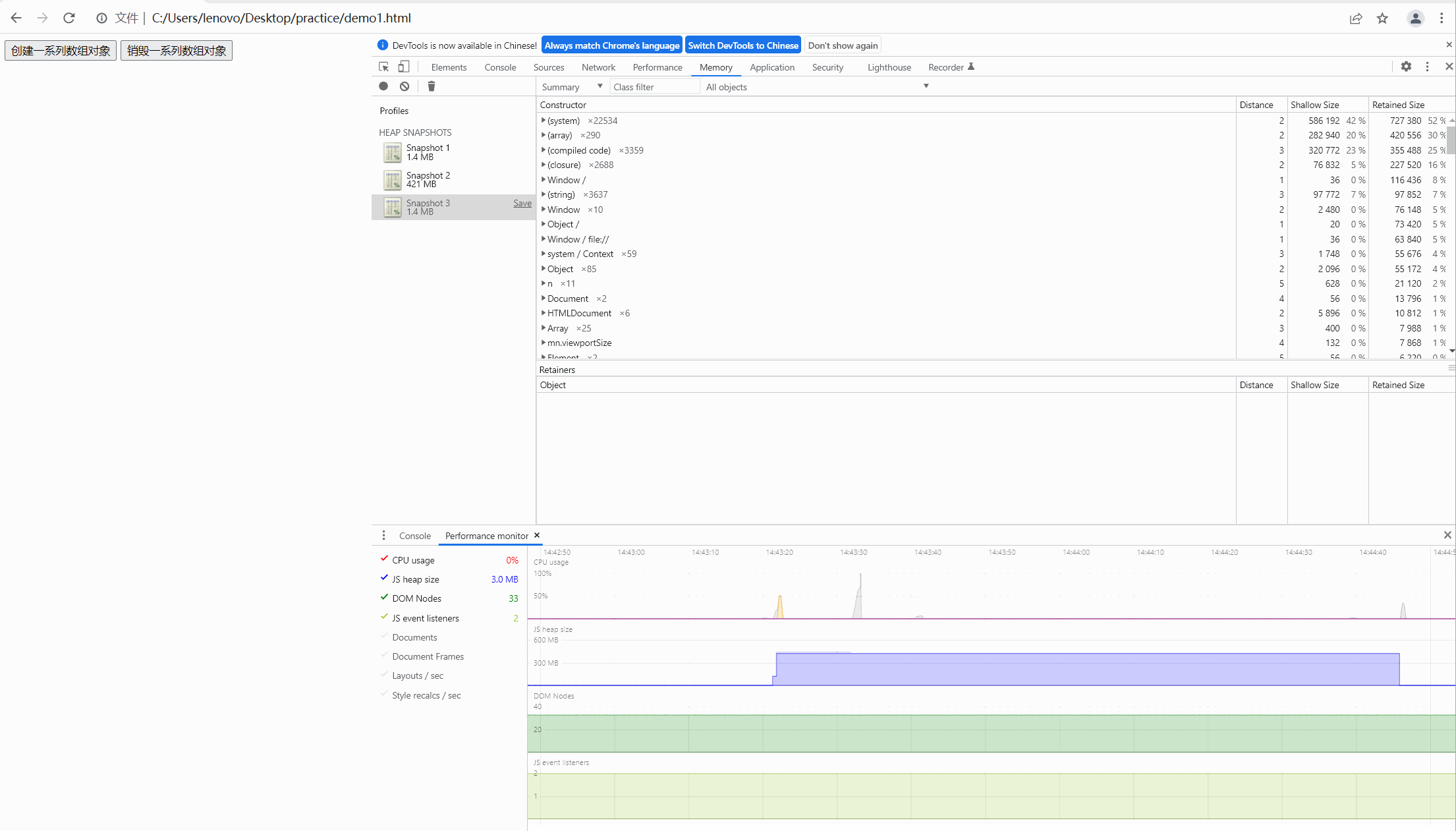
很明显,此时的内存经过我们手动释放后回到最初时的内存大小
# 垃圾回收及算法
JavaScript中的内存管理是自动的,在创建对象时会自动分配内存,当对象不在被引用或者不能从根上访问时,就会被当做垃圾给回收掉。 |
注意:**JavaScript 中的 ** 可达对象简单的说就是可以访问到的对象,不管是通过引用还是作用域链的方式,只要能访问到的就称之为可达对象。可达对象的可达是有一个标准的,就是必须从根上出发是否能被找到;这里的根可以理解为 JavaScript 中的全局变量对象,在浏览器环境中就是 window、在 Node 环境中就是 global。
为了更好的理解引用的概念,看下面这一段代码:
let person = { | |
name: '一碗周', | |
} | |
let man = person | |
person = null |
图解如下:
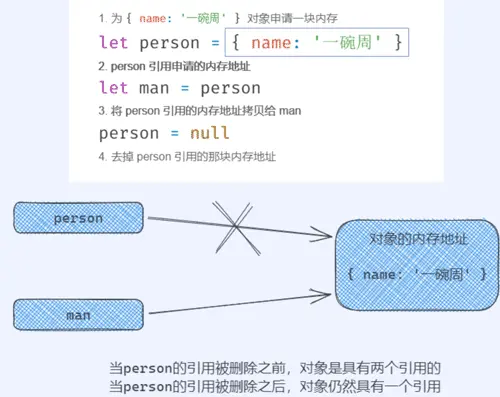
根据上面那个图我们可以看到,最终这个 { name: '一碗周' } 是不会被当做垃圾给回收掉的,因为还具有一个引用。
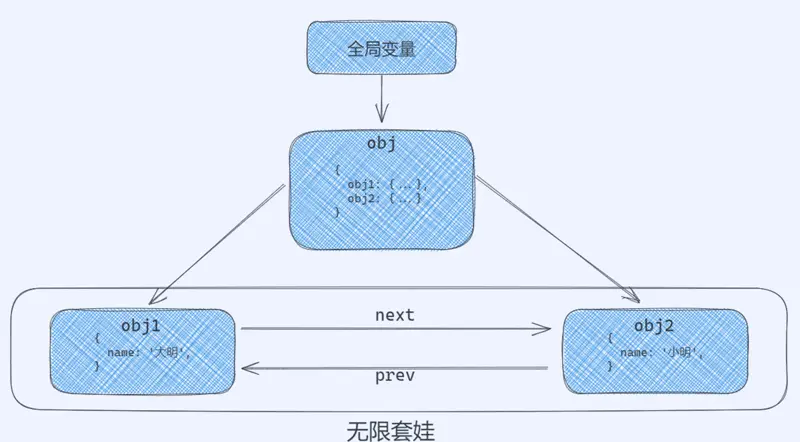
现在我们来理解一下可达对象,代码如下:
function groupObj(obj1, obj2) { | |
obj1.next = obj2 | |
obj2.prev = obj1 | |
return { | |
obj1, | |
obj2, | |
} | |
} | |
let obj = groupObj({ name: '大明' }, { name: '小明' }) |
调用 groupObj() 函数的的结果 obj 是一个包含两个对象的一个对象,其中 obj.obj1 的 next 属性指向 obj.obj2 ;而 obj.obj2 的 prev 属性又指向 obj.obj2 。最终形成了一个无限套娃。
如下图:
现在来看下面这段代码:
delete obj.obj1 | |
delete obj.obj2.prev |
我们删除 obj 对象中的 obj1 对象的引用和 obj.obj2 中的 prev 属性对 obj1 的引用。
图解如下:
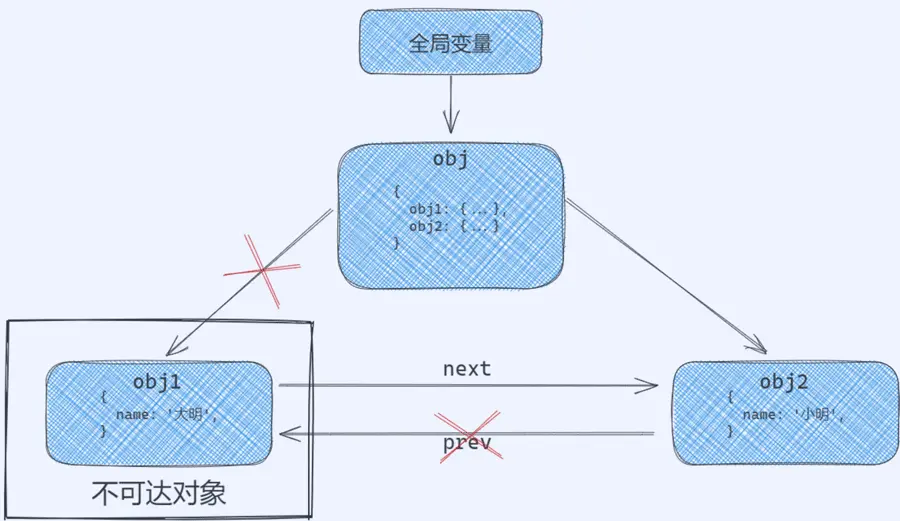
此时的 obj1 就被当做垃圾给回收了。
# GC 算法
GC 是 Garbage collection 的简写,也就是垃圾回收。当 GC 进行工作的时候,它可以找到内存中的垃圾、并释放和回收空间,回收之后方便我们后续的进行使用。
在 GC 中的垃圾包括程序中不在需要使用的对象以及程序中不能再访问到的对象都会被当做垃圾。
GC 算法就是工作时查找和回收所遵循的规则,常见的 GC 算法有如下几种:
- ** 引用计数:** 通过一个数字来记录引用次数,通过判断当前数字是不是 0 来判断对象是不是一个垃圾。
- ** 标记清除:** 在工作时为对象添加一个标记来判断是不是垃圾。
- ** 标记整理:** 与标记清除类似。
- ** 分代回收:**V8 中使用的垃圾回收机制。
# 引用计数算法
引用计数算法的核心思想就是设置一个引用计数器,判断当前引用数是否为 0 ,从而决定当前对象是不是一个垃圾,从而垃圾回收机制开始工作,释放这块内存。
引用计数算法的核心就是引用计数器 ,由于引用计数器的存在,也就导致该算法与其他 GC 算法有所差别。
引用计数器的改变是在引用关系发生改变时就会发生变化,当引用计数器变为 0 的时候,该对象就会被当做垃圾回收。
现在我们通过一段代码来看一下:
// {name: ' 一碗周 '} 的引用计数器 + 1 | |
let person = { | |
name: '一碗周', | |
} | |
// 又增加了一个引用,引用计数器 + 1 | |
let man = person | |
// 取消一个引用,引用计数器 - 1 | |
person = null | |
// 取消一个引用,引用计数器 - 1。此时 {name: ' 一碗周 '} 的内存就会被当做垃圾回收 | |
man = null |
引用计数算法的优点如下:
- 发现垃圾时立即回收;
- 最大限度减少程序暂停,这里因为发现垃圾就立刻回收了,减少了程序因内存爆满而被迫停止的现象。
缺点如下:
- 无法回收循环引用的对象;
就比如下面这段代码:
function fun() { | |
const obj1 = {} | |
const obj2 = {} | |
obj1.next = obj2 | |
obj2.prev = obj1 | |
return '一碗周' | |
} | |
fun() |
上面的代码中,当函数执行完成之后函数体的内容已经是没有作用的了,但是由于 obj1 和 obj2 都存在不止 1 个引用,导致两种都无法被回收,就造成了空间内存的浪费。
- 时间开销大,这是因为引用计数算法需要时刻的去监控引用计数器的变化。
# 标记清除算法
标记清除算法解决了引用计数算法的⼀些问题, 并且实现较为简单, 在 V8 引擎中会有被⼤量的使⽤到。
在使⽤标记清除算法时,未引用对象并不会被立即回收。取⽽代之的做法是,垃圾对象将⼀直累计到内存耗尽为⽌。当内存耗尽时,程序将会被挂起,垃圾回收开始执行。当所有的未引用对象被清理完毕 时,程序才会继续执行。该算法的核心思想就是将整个垃圾回收操作分为标记和清除两个阶段完成。
第一个阶段就是遍历所有对象,标记所有的可达对象;第二个阶段就是遍历所有对象清除没有标记的对象,同时会抹掉所有已经标记的对象,便于下次的工作。
为了区分可用对象与垃圾对象,我们需要在每⼀个对象中记录对象的状态。 因此, 我们在每⼀个对象中加⼊了⼀个特殊的布尔类型的域, 叫做 marked 。 默认情况下, 对象被创建时处于未标记状态。 所以, marked 域被初始化为 false 。
标记清除算法的图解如下图所示:
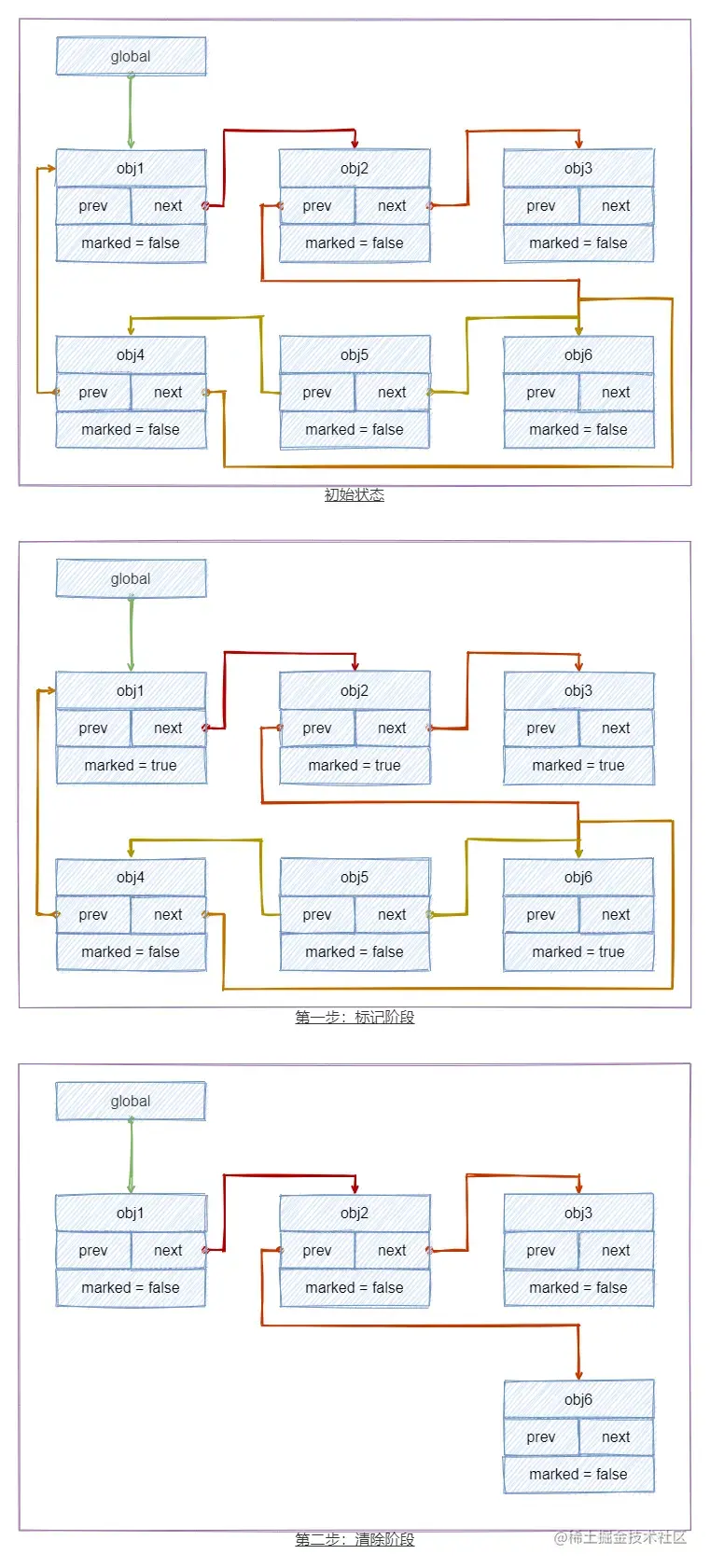
进行垃圾回收完毕之后,将回收的内存放在空闲链表中方便我们后续使用。
标记清除算法最大的优点就是解决了引用计数算法无法回收循环引用的对象的问题 。就比如下面这段代码:
function fun() { | |
const obj1 = {}, | |
obj2 = {}, | |
obj3 = {}, | |
obj4 = {}, | |
obj5 = {}, | |
obj6 = {} | |
obj1.next = obj2 | |
obj2.next = obj3 | |
obj2.prev = obj6 | |
obj4.next = obj6 | |
obj4.prev = obj1 | |
obj5.next = obj4 | |
obj5.prev = obj6 | |
return obj1 | |
} | |
const obj = fun() |
当函数执行完毕后 obj4 的引用并不是 0,但是使用引用计数算法并不能将其作为垃圾回收掉,而使用标记清除算法就解决了这个问题。
而标记清除算法的缺点也是有的,这种算法会导致内存碎片化,地址不连续;还有就是使用标记清除算法即使发现了垃圾对象不里能立刻清除,需要到第二次去清除。
# 标记整理算法
标记整理算法可以看做是标记清除算法的增强型,其步骤也是分为标记和清除两个阶段。
但是标记整理算法那的清除阶段会先进行整理,移动对象的位置,最后进行清除。
步骤如下图:
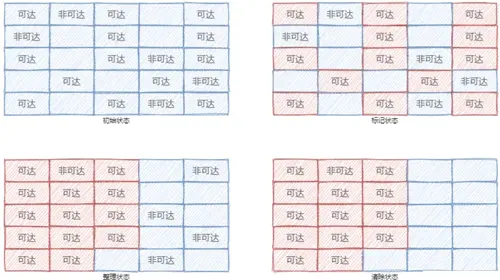
# V8 中的内存管理
# V8 是什么
V8 是一款主流的 JavaScript 执行引擎,现在的 Node.js 和大多数浏览器都采用 V8 作为 JavaScript 的引擎。V8 的编译功能采用的是及时编译,也称为动态翻译或运行时编译,是一种执行计算机代码的方法,这种方法涉及在程序执行过程中(在执行期)而不是在执行之前进行编译。
V8 引擎对内存是设有上限的,在 64 位操作系统下上限是 1.5G 的,而 32 位操作系统的上限是 800 兆的。至于为什么设置内存上限主要是内容 V8 引擎主要是为浏览器而准备的,不适合太大的空间;还有一点就是这个大小的垃圾回收是很快的,用户几乎没有感觉,从而增加用户体验。
# V8 垃圾回收策略
V8 引擎采用的是分代回收的思想,主要是将我们的内存按照一定的规则分成两类,一个是新生代存储区,另一个是老生代存储区。
新生代的对象为存活时间较短的对象,简单来说就是新产生的对象,通常只支持一定的容量(64 位操作系统 32 兆、32 位操作系统 16 兆),而老生代的对象为存活事件较长或常驻内存的对象,简单来说就是经历过新生代垃圾回收后还存活下来的对象,容量通常比较大。
下图展示了 V8 中的内存:

V8 引擎会根据不同的对象采用不同的 GC 算法,V8 中常用的 GC 算法如下:
- 分代回收
- 空间复制
- 标记清除
- 标记整理
- 标记增量
# 新生代对象垃圾回收
上面我们也介绍了,新生代中存放的是存活时间较短的对象。新生代对象回收过程采用的是复制算法和标记整理算法。
复制算法将我们的新生代内存区域划分为两个相同大小的空间,我们将当前使用状态的空间称之为 From 状态,空间状态的空间称之为 To 状态,
如下图所示:

我们将活动的对象全部存储到 From 空间,当空间接近满的时候,就会触发垃圾回收。
首先需要将新生代 From 空间中的活动对象做标记整理,标记整理完成之后将标记后的活动对象拷贝到 To 空间并将没有进行标记的对象进行回收;最后将 From 空间和 To 空间进行交换。
还有一点需要说的就是在进行对象拷贝的时候,会出现新生代对象移动至老生代对象中。
这些被移动的对象是具有指定条件的,主要有两种:
- 经过一轮垃圾回收还存活的新生代对象会被移动到老生代对象中
- 在 To 空间占用率超过了 25%,这个对象也会被移动到老生代对象中(25% 的原因是怕影响后续内存分配)
如此可知,新生代对象的垃圾回收采用的方案是空间换时间。
# 老生代对象垃圾回收
老生代区域存放的对象就是存活时间长、占用空间大的对象。也正是因为其存活的时间长且占用空间大,也就导致了不能采用复制算法,如果采用复制算法那就会造成时间长和空间浪费的现象。
老生代对象一般采用标记清除、标记整理和增量标记算法进行垃圾回收。
在清除阶段主要才采用标记清除算法来进行回收,当一段时候后,就会产生大量不连续的内存碎片,过多的碎片无法分配足够的内存时,就会采用标记整理算法来整理我们的空间碎片。
老生代对象的垃圾回收会采用增量标记算法来优化垃圾回收的过程,增量标记算法如下图所示:
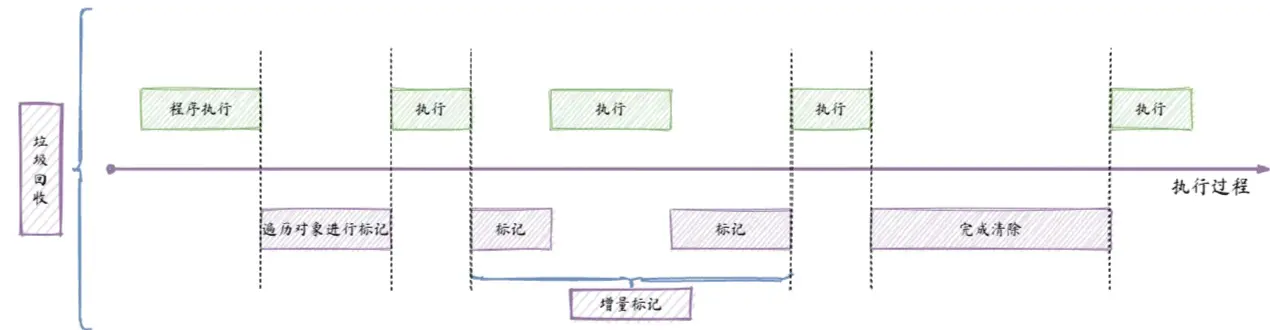
由于 JavaScript 是单线程,所以程序执行和垃圾回收同时只能运行一个,这就会导致在执行垃圾回收的时候程序卡顿,这样给用户的体验肯定是不好的。
所以提出了增量标记,在程序运行时,程序先跑一段时间,然后进行进行初步的标记,这个标记有可能只标记直接可达的对象,然后程序继续跑一段时间,在进行增量标记 ,也即是标记哪些间接可达的对象。由此反复,直至结束。
# Performance 工具
由于 JavaScript 没有给我们提供操作内存的 API,只能靠本身提供的内存管理,但是我们并不知道实际上的内存管理是什么样的。而有时我们需要时刻关注内存的使用情况,Performance 工具提供了多种监控内存的方式。
# Performance 使用步骤
首先我们打开 Chrome 浏览器(这里我们使用的是 Chrome 浏览器,其他浏览器也是可以的),在地址栏中输入我们的目标地址,然后打开开发者工具,选择【性能】面板。
选择性能面板后开启录制功能,然后去访问具体界面,模仿用户去执行一些操作,然后停止录制,最后我们可以在分析界面中分析记录的内存信息。
结果如下图所示:
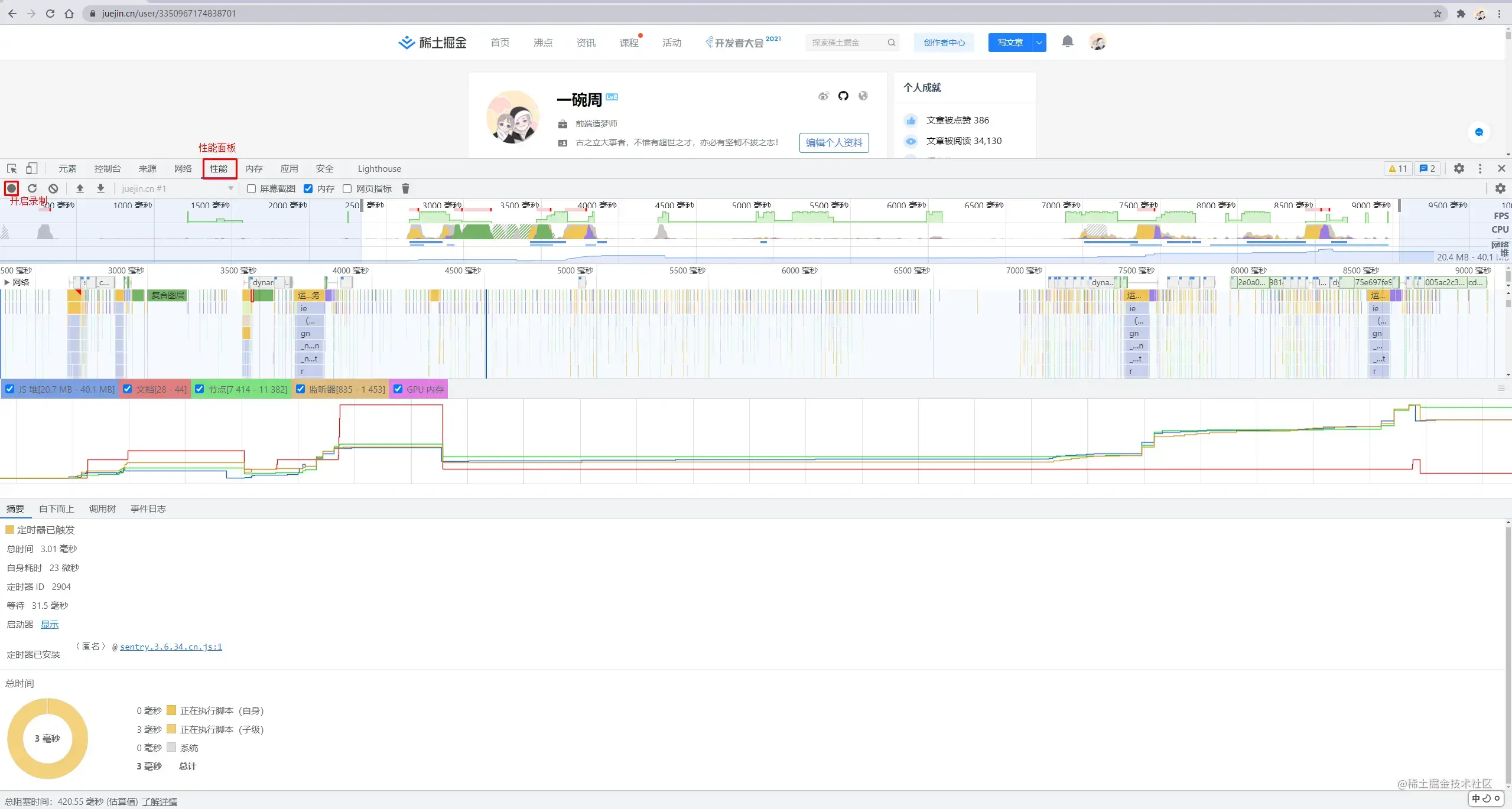
# 内存问题的体现
出现内存的问题主要有如下几种表现:
- 页面出现延迟加载或经常性暂停,它的底层就伴随着频繁的垃圾回收的执行;为什么会频繁的进行垃圾回收,可能是一些代码直接导致内存爆满而且需要立刻进行垃圾回收。
关于这个问题我们可以通过内存变化图进行分析其原因:
- 页面持续性出现糟糕的性能表现,也就是说在我们使用的过程中,页面给我们的感觉就是一直不好用,它的底层我们一般认为都会存在内存膨胀,所谓的内存膨胀就是当前页面为了达到某种速度从而申请远大于本身需要的内存,申请的这个存在超过了我们设备本身所能提供的大小,这个时候我们就能感知到一个持续性的糟糕性能的体验。
导致内存膨胀的问题有可能是我们代码的问题,也有可能是设备本身就很差劲,想要分析定位并解决的话需要我们在多个设备上进行反复的测试
- 页面的性能随着时间的延长导致页面越来越差,加载时间越来越长,出现这种问题的原因可能是由于代码的原因出现内存泄露。
想要检测内存是否泄漏,我们可以通过内存总视图来监听我们的内存,如果内存是持续升高的,就可能已经出现了内存泄露。
# 监控内存的方式
在浏览器中监控内存主要有以下几种方式:
- 浏览器提供的任务管理器
- Timeline 时序图
- 堆快照查找分离 DOM
- 判断是否存在频繁的垃圾回收
接下来我们就分别讲解这几种方式。
# 任务管理器监控内存
在浏览器中按【Shift】+【ESC】键即可打开浏览器提供的任务管理器,下图展示了 Chrome 浏览器中的任务管理器,我们来解读一下
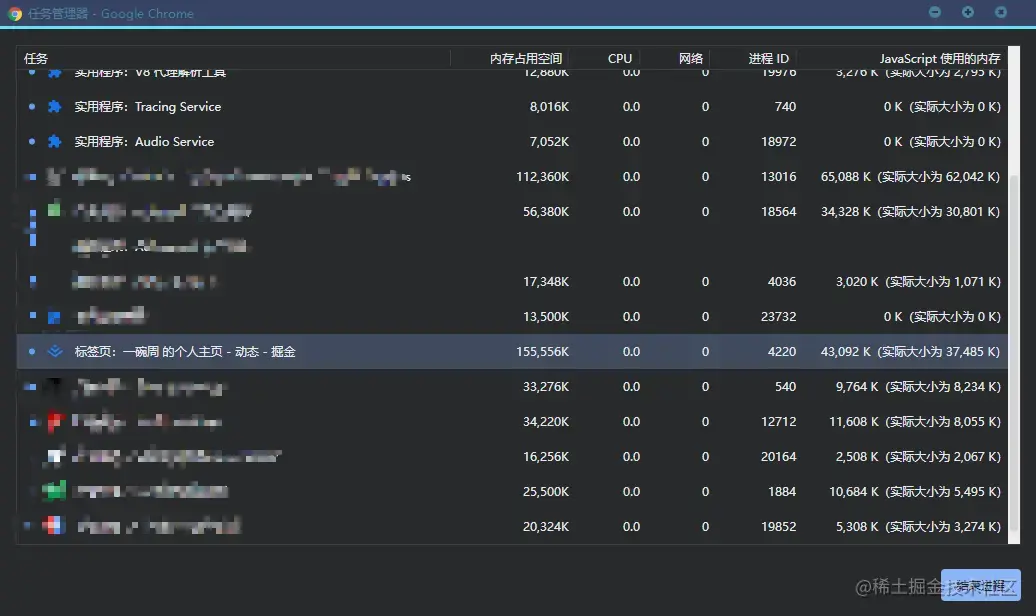
上图中我们可以看到【掘金】标签页的【内存占用空间】表示的的这个页面的 DOM 在浏览器中所占的内存,如果不断增加就表示有新的 DOM 在创建;而后面的【JavaScript 使用的内存】(默认不开启,需要通过右键开启)表示的是 JavaScript 中的堆,而括号中的大小表示 JavaScript 中的所有可达对象。
# Timeline 记录内存
上面描述的浏览器中提供的任务管理器只能用来帮助我们判断页面是否存在问题,却不能定位页面的问题。
Timeline 是 Performance 工具中的一个小的选项卡,其中以毫秒为单位记录了页面中的情况,从而可以帮助我们更简单的定位问题。
# 堆快照查找分离 DOM
堆快照是很有针对性的查找当前的界面对象中是否存在一些分离的 DOM,分离 DOM 的存在也就是存在内存泄漏。
首先我们先要弄清楚 DOM 有几种状态:
- 首先,DOM 对象存在 DOM 树中,这属于正常的 DOM
- 然后,不存在 DOM 树中且不存在 JS 引用,这属于垃圾 DOM 对象,是需要被回收的
- 最后,不存在 DOM 树中但是存在 JS 引用,这就是分离 DOM,需要我们手动进行释放。
查找分离 DOM 的步骤:打开开发者工具→【内存面板】→【用户配置】→【获取快照】→在【过滤器】中输入 Detached 来查找分离 DOM,
如下图所示:
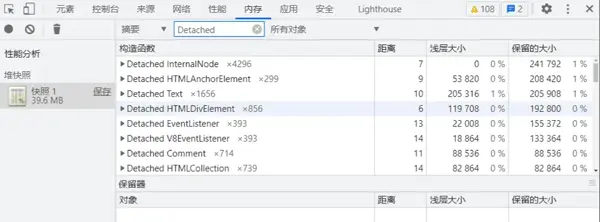
查找到创建的分离 DOM 后,我们找到该 DOM 的引用,然后进行释放。
# 判断是否存在频繁的垃圾回收
因为 GC 工作时应用程序是停止的,如果当前垃圾回收频繁工作,而且时间过长的话对页面来说很不友好,会导致应用假死说我状态,用户使用中会感知应用有卡顿。
我们可以通过如下方式进行判断是否存在频繁的垃圾回收,具体如下:
- 通过 Timeline 时序图判断,对当前性能面板中的内存走势进行监控,如果其中频繁的上升下降,就出现了频繁的垃圾回收。这个时候要定位代码,看看是执行什么的时候造成了这种情况。
- 使用浏览器任务管理器会简单一些,任务管理器中主要是数值的变化,其数据频繁的瞬间增加减小,也是频繁的垃圾回收。